
접촉 조사(Contact survey)는 다방면에서 활용할 수 있는 매우 중요한 정보이다. 다른 글에서도 언급했듯 질병학에서 매우 활용도가 높고, 이외에도 여러 사회학 연구 등에서 많이 활용된다. 예를 들어, 글쓴이의 대학원 시절, 유럽의 큰 조사였던 POLYMOD 프로젝트나 국내 접촉 조사 등을 활용하여 수두 바이러스라던가, COVID-19 등의 확산을 연구한 경험이 있다. 질병 확산을 접촉과 결부시켜 설명할 수 있기 때문에, 그 정도가 평균 접촉수(Average contact)이나 접촉률(Contact rate)에 상관이 있다고 생각하고, 질병 확산을 설명한다.
질병 확산의 방식에 따라, 전체 인구수를 어떻게 나눌 지를 매번 결정해야한다. 이에 따라서, 접촉률을 알아야하는 그룹이 달라진다. 우리가 원하는 그룹에 따라서 접촉 조사를 다르게 이용하여야 하는데, 이 포스트에서는 그 과정을 설명해보려 한다. 더하여서, 그룹을 나이같은 것으로 나누면, 나이가 별로 바뀌지 않았음에도 조사에선 접촉률이 너무 크게 변하는 경우가 있다. 이럴 때, 이런 것을 어떻게 스무딩(Smoothing)할 수 있는지도 설명해보려 한다.
평균 접촉수와 접촉률
먼저, 접촉 조사를 사용하기 전에, 평균 접촉수와 전체 접속수, 그리고 접촉률에 대해 정확히 알고 있어야 한다. 굉장히 쉬운 이야기지만, 처음 접했을 때는 혼동될 수 있는 점이 있다. 먼저 아래 그림과 같이, 조사 인구의 나이가 10대, 20대, 30대로 이루어져 있다고 하자. 더하여, 전체 인구수가 10대 400만명, 20대 600만명, 30대 700만명있다고 하자. 즉, 인구수 $N$ 벡터를 아래와 같이 정의한다 ($M$은 100만(million)을 의미한다).
\[N=[4M, 6M, 7M]\]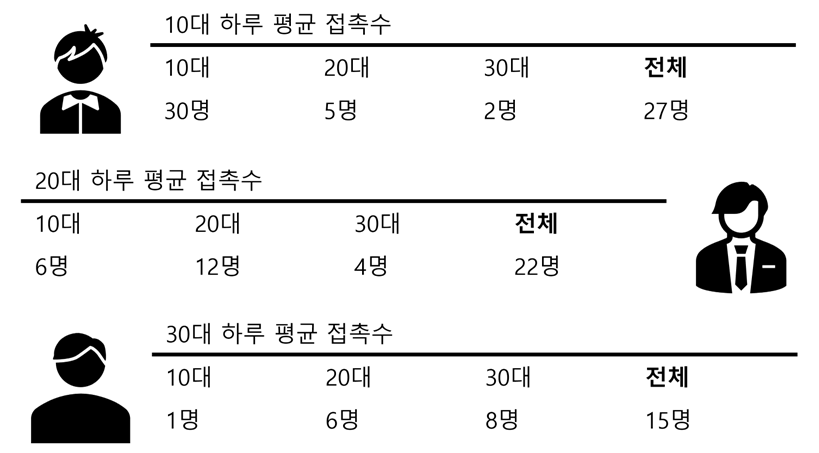
위와 같이, 접촉 조사가 이루어 졌고, 여기에서 10대, 20대, 30대의 각각 나이대별 평균 접촉수를 조사했다고 하자. 그렇다면, 여기에서, 평균 접촉수로 이루어진 행렬을 구성할 수 있다. 각 열을 조사자의 나이대 그리고 각 행을 접촉 조사로 알아낸 평균 접촉수를 적는다면, 평균 접촉수를 나타내는 행렬 $m$의 요소 $m_{ij}$는 $j$번째 나이대의 사람이 $i$번째 나이대의 사람을 평균 얼마나 만나는 지를 나타낼 것이다.
\[m=\begin{bmatrix} 30 & 6 & 1 \\ 5 & 12 & 6 \\ 2 & 4 & 8 \end{bmatrix}\]만약에, 이 조사의 결과를 전체 인구에 적용할 수 있다면, $i$번째 나이대의 모든 사람이 $j$번째 나이대의 사람과 만난 전체 접촉수는 아래와 같이 알 수 있다.
\[C_{ij}:=m_{ij}N_j\]인구 전체의 접촉수를 나타내는 행렬 $C$를 위와 같이 정의해보자. 그렇다면, 전체 접촉수 행렬 $C$는 아래와 같다.
\[C=\begin{bmatrix} 120M & 36M & 7M \\ 20M & 72M & 42M \\ 8M & 24M & 56M \end{bmatrix}\]$i$번째 나이대의 인구 전체가 만난 $j$번째 나이대의 인구수는, 자명하게도, $j$번째 나이대의 인구 전체가 만난 $i$번째 나이대의 인구수와 같아야만 한다. 이를, 접촉의 상호성(Reciprocity)이라고 말한다. 즉, $C$ 행렬은 대칭(Symmetric)이어야만 하고, 이를 수식으로 나타내면 아래와 같다.
\[C=C^T\]하지만, 일반적으로, 우리는 전수 조사를 하지 못하기 때문에, 위에서 얻은 결과와 같이 이 행렬이 대칭이 아닐 가능성이 높다. 여기에서, 우리는 이 행렬을 대칭화시킨다.
\[C\leftarrow \frac{C+C^T}{2}\]이 방법을 적용하면, 접촉의 상호성를 만족하는 총 접촉수 행렬은 아래와 같다.
\[C=\begin{bmatrix} 120M & 28M & 7.5M \\ 28M & 72M & 33M \\ 7.5M & 33M & 56M \end{bmatrix}\]하지만 보는 것과 같이, 상당히 숫자의 단위가 크다. 이것은 실제에서 사용하기에 많은 문제를 일으킨다. 그리고, 우리는 인구수와 결부해서 이 행렬을 많이 사용해야하는데, 단위에 혼동이 있을 수 있다. 그래서, 우리는 접촉률 행렬 $r$을 아래와 같이 정의하여, 실제에서 사용하게 된다.
\[r_{ij}:=\frac{m_{ij}}{N_i}=\frac{C_{ij}}{N_iN_j}\]정의에서 알 수 있듯, 접촉의 상호성에 의해서, 이 행렬은 대칭이다.
\[r=r^T\]위에서 구한, 접촉 행렬을 바탕으로 구하게 되면, 아래와 같다.
\[r=\begin{bmatrix} 7.5\times10^{-6} & 1.17\times10^{-6} & 2.68\times10^{-7} \\ 1.17\times10^{-6} & 2\times10^{-6} & 7.86\times10^{-7} \\ 2.68\times10^{-7} & 7.86\times10^{-7} & 1.14\times10^{-6} \end{bmatrix}\]이 접촉률 행렬을 활용하면, 여러 연구를 진행할 수 있다.
스무딩
서론에 언급했듯이, 앞의 경우와 달리 나이대가 촘촘한 경우, 되게 가까운 그룹사이에 조사된 수가 너무 많이 다를 수 있다. 이는, 전체 인구로 봤을 땐, 조금 비현실적인 상황이기 때문에, 그 간극을 메우는 작업을 필요로 한다. 이를 위해, 일반화 가법모형(Generalized additive model, gam)을 음이항분포(Negative binomial distribution)과 함께 적용한다. 이론적인 설명은 다음 포스트로 미루고, 여기에서는 실제 코드를 어떤 식으로 적용하는 지 보여줄 예정이다.
gam을 활용하기 위해서는 R의 mgcv 라이브러리를 사용하여야한다.
library("mgcv")
조사 데이터를 불러오는 변수를 만들고, 각 조사 참여자들이 각 그룹의 인원을 얼마나 만났는 지를 정리하여야한다. 이 부분은 이번 포스트와는 관련 없는 부분이기 때문에 생략하도록 하겠다. 다만, 주의해야할 점이 있다. 이 과정에서, 흔히, 각 인원이 만난 사람을 정리할 때, 만난 사람만을 정리할 텐데, 만나지 못한 사람은 0으로 처리하여 변수에 통합하여야 한다. 즉, 아래와 같이 조사가 되었다고 하자.
| part_id | part_age | cont_age | contact_number |
|---|---|---|---|
| 1 | 10 | 10 | 35 |
| 1 | 10 | 11 | 15 |
| 1 | 10 | 12 | 3 |
| 2 | 11 | 11 | 33 |
| 2 | 11 | 12 | 14 |
| 3 | 12 | 12 | 40 |
그렇다면, 이 상태로 진행하는 것이 아니라, 비어있는 부분을 0(만나지 못했다)으로 조사한 것이기 때문에 이를 반영하여 변수를 아래와 같이 설정하여야 한다.
| part_id | part_age | cont_age | contact_number |
|---|---|---|---|
| 1 | 10 | 10 | 35 |
| 1 | 10 | 11 | 15 |
| 1 | 10 | 12 | 3 |
| 2 | 11 | 10 | 0 |
| 2 | 11 | 11 | 33 |
| 2 | 11 | 12 | 14 |
| 3 | 12 | 12 | 0 |
| 3 | 12 | 12 | 0 |
| 3 | 12 | 12 | 40 |
만약에 더 많은 나이대를 대상으로 조사한다면, 보고되지 않은 모든 나이의 접촉수를 0으로 해야한다. 이 변수를 dat라고 하면, 우리는 gam 함수를 적용하여 Regression 변수를 만들어 낼 수 있다.
gam_result_nb = gam(
cont ~ te(cnt_age, part_age, k=15, bs="tp"), negbin(c(1:10)),
optimizer="perf",
weights=weight,
data=dat
)
여기에서 만들어진 Regression 변수 gam_result_nb를 사용하면, 인풋 변수 두가지에 대해 값을 구할 수 있다. 이는 predict 함수를 사용하면, 쉽게 구할 수 있다. 아래, 함수에서 age1, age2 변수는 우리가 알고 싶은 접촉의 두 나이를 모은 두 벡터를 의미한다.
gam_result = predict(
gam_result_nb,
type = "response",
newdata = data.frame(part_age = age1,
cnt_age = age2)
)
이렇게 우리는 스무딩된 평균 접촉수를 얻을 수 있고, 여기에 위에서 언급한 접촉의 상관성을 적용하여 보정하면, 최종적으로 아래와 같은 접촉률 행렬을 얻을 수 있다.
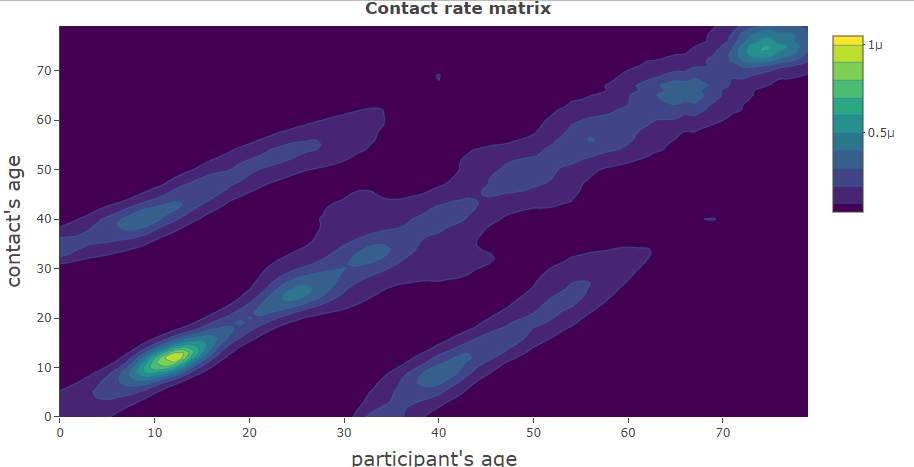
Weight?
앞에서 gam 함수를 적용할 때, 자료 변수의 weight 항목을 사용하는 것을 볼 수 있다. 그렇다면, 이 과정에서 weight는 어떤 의미를 가질까? 조사를 활용한 분석 중에 weight로 보정한다는 것은 과정에서 중요시하는 정도를 변화시키는 것을 의미한다. 우리는, 접촉 조사가 전체 인구를 최대한 닮기를 바란다. 위 과정에서 weight는 우리 조사에서의 접촉이 가지는 가치를 전체 인구의 접촉으로 보정하여 각 인원의 접촉의 중요도를 보정하기 위해 사용된다.
보통 가장 오래 접촉하는 사람은 주로 같은 가구에 속한 사람일 때가 많다. 즉, 우리 접촉 조사에서, 가구 구성원이 접촉수에 굉장히 큰 영향을 미친다. 여기에서 착안하여, POLYMOD 프로젝트에선 조사에서의 가구수 비율과 실제 가구수 비율을 비교하여, 그 배수를 weight로 주게 된다. 또 다른 연구에서는, 조사에서의 인구 비율과 실제 인구의 비율을 비교하여 그 배수를 weight로 주는 방법 또한 있다. 각 자료마다, 원하는 방향성이 다르고, 접촉의 어떤 면을 강조하여 설명할 지가 다르기 때문에, 각 상황에 맞게 적절한 weight를 주는 것이 좋을 것이다.
참고자료
위 과정은 POLYMOD 프로젝트를 참고하고, 전체적인 과정은 Niel Hens와 Jacco Wallinga의 설명 논문을 참고하였다.