
우리는 실생활에서도 가장 좋은 방법을 찾으려는 노력을 많이 한다. 하루 일정을 세울 때나, 예산을 분배할 때, 난방을 조절할 때 등등, 최소한의 노력이나 소비로 최대한의 효과를 바란다. 이런 종류의 문제들은, 흔히, 최적화 문제(Optimal control problem)라고 불리고, 수학적으로도, 계산적으로도 상당히 어려운 문제에 속한다. 데이터를 분석할 때에도, 상당히 많은 종류의 최적화 문제를 설계하게 되는데, 그 중 모수 추정(Parameter estimation)은 거의 모든 분석에서 필수적으로 들어가는 최적화 문제이다. 신경망 모델의 Weight와 bias 등을 구하거나, 감염 모델에서 감염 계수를 구하는 과정이 여기에 속한다.
최적화 문제는 그 자체로 풀기가 상당히 어려운 편에 속하기 때문에, 문제 해결 과정을 어느 정도 계획해야 한다. 정규화(Regularization)을 사용할 것인지, 사용한다면 어떤 방식으로 사용할 것인지. 데이터를 어떤 방식으로 사용할 것인지. 어떤 모델을 사용하여 데이터를 분석할 것인지. 특히, 어떤 최적화 알고리즘을 사용할 지도 정해야 하는데, 이는 계산 시간에 큰 영향을 준다. 머신러닝에서 많이 쓰이는 알고리즘은 Gradient-based method이다. 어떤 점에서의 함수값의 줄어드는 방향은 gradient의 반대 방향임을 이용하여 최적화를 하는 방법이다. 가장 대표적인 알고리즘은 gradient descent method(또는, steepest descent method)이다. 최적화의 아이디어를 그대로 실현한 것으로, 대표적인 수식은 아래와 같다. 목적 함수(objective function, $J$)가 주어졌을 때,
\[\begin{equation} \theta \leftarrow \theta-\epsilon\nabla_\theta J(\theta) \end{equation}\]Gradient descent에서의 어려움
Gradiet descent는 간단하지만, 적절한 학습률(learning rate, $\epsilon$)을 정하기 위해 많은 시행착오가 필요하다. 너무 작은 학습률을 사용하면, 필요한 것보다 더 많은 양의 계산을 해야 하고, 반대로, 너무 큰 학습률을 이용하면, 최적화가 이루어지지 않고 여러 점들을 반복하게 된다. 그래서, 진행하는 방향에 적절한 momentum을 주어서, 최적화 속도에 적절한 가속을 주는 방법이 있다. 또는, 최적화를 진행하면서 학습률을 점점 줄여서 최적화가 적절히 이루어질 수 있게 변형할 수도 있다. 당연히, 최적화 상황에 따라 적절히 변형해야 하는데, 이런 부류의 알고리즘들을 adaptive 하다고 한다.
또 다른 어려움은 parameter의 초깃값(initial point)을 정하는 것이다. Gradient descent는 local minima에 빠질 위험이 크다. 이를 극복하기 위해, simulated annealing, particle swarm algorithm 등의 global search algorithm 등을 활용하지만, 이 알고리즘들이 언제나 global minimum을 보장하진 않는다. 반면, 머신러닝은 최적화 대상이 되는 목적 함수와 실제 사용하는 목적 함수가 다르다. 이는 최적화 문제를 어렵게 만들기도 하지만, 이런 점 덕분에 찾은 parameter 값이 local minimum인지, global minimum인지 여부가 너무 중요한 문제이지 않게 된다. 그래서, 일전에 설명한 최적화 속도를 해결하기 위한 방법을 먼저 소개하려 한다. 바로 Adam(Adaptive moments) algorithm이다.
Adam 이전의 알고리즘
교과서에서 Adam을 살펴볼 때, 상세한 정보는 Deep Learning 책을 참고하게 한다. 이 책의 흐름을 이해하기 위해, Adam이 소개되기 전의 알고리즘들을 먼저 이해하는 것이 좋다. 책에서는 먼저, 최적화 속도에 어떤 momentum을 주는 지를 살펴본다. 이후에, 학습률을 조작하는 adaptive algorithm를 여러가지 설명한다.
Momentum
Gradient descent를 이용하여 최적화를 진행하면서, 과거에 진행한 방향에 가속을 준다면, 너무 느린 최적화 알고리즘을 보완할 수 있다. 또한 미니 배치 단위의 학습에서, 각 미니 배치에서 주는 학습을 계속해서 반영하여 진행한다. 가속도는 각 학습에서 진행한 학습을 계속해서 더하여 구하게 된다. $m$ size의 미니 배치와, parameter $\theta$를 사용한 신경망 $f(x;\theta,y)$을 이용하면, 아래와 같이 정할 수 있다.
\[\begin{equation} \mathbf{v} \leftarrow \alpha \mathbf{v} - \epsilon\nabla_\theta J(\theta)=\alpha \mathbf{v} -\epsilon\nabla_\theta\left(\frac{1}{m}\sum^m_{i=1}L\left(f\left(\mathbf{x}^{(i)};\theta\right),\mathbf{y}^{(i)}\right)\right) \end{equation}\]$\alpha$는 momentum parameter로 얼마나 momentum을 현재 최적화에 반영할 것인지를 정하는 수이다. 만약에, 모든 최적화가 같은 방향 $\mathbf{g}$로 이루어진다면, 계속 최적화가 가속되어 아래 속도까지 가속될 것이다.
\[\begin{equation} \{-\epsilon\mathbf{g},-(\alpha+1)\epsilon\mathbf{g},-(\alpha^2 + \alpha +1)\epsilon\mathbf{g},-(\alpha^3+\alpha^2+\alpha+1)\epsilon\mathbf{g},\cdots\}_1^\infty\rightarrow-\frac{\epsilon}{1-\alpha}\mathbf{g} \end{equation}\]Momentum을 활용한 알고리즘은 아래와 같이 정리할 수 있다.
Gradient descent with a momentum
While tolerance 만족이 안 되면
- Gradient를 계산한다. $\mathbf{g}=\frac{1}{m}\nabla_\theta\sum^m_{i=1}L\left(f\left(\mathbf{x}^{(i)};\theta\right),\mathbf{y}^{(i)}\right)$
- 현재 속도를 계산한다. $\mathbf{v}\leftarrow\alpha\mathbf{v}-\epsilon\mathbf{g}$
- Parameter를 업데이트한다. $\theta\leftarrow\theta+\mathbf{v}$
End While
여기에 가속에 대해 Nesterov의 아이디어를 차용하여 correction한다. 이것을 Nesterov’s momentum이라고 하고, 아래와 같이 속도를 다르게 업데이트한다.
\[\begin{equation} \mathbf{v} \leftarrow \alpha \mathbf{v} - \epsilon\nabla_\theta J(\theta+\alpha \mathbf{v})=\alpha \mathbf{v} -\epsilon\nabla_\theta\left(\frac{1}{m}\sum^m_{i=1}L\left(f\left(\mathbf{x}^{(i)};\theta+\alpha \mathbf{v}\right),\mathbf{y}^{(i)}\right)\right) \end{equation}\]간단한 변화로, (batch) gradient descent에서 빠른 수렴을 이루어 낼 수 있다. 하지만, 동시에 momentum parameter, $\alpha$를 또 하나의 hyperparameter로 추가하게 되어, 모델에 영향을 크게 주는 변수가 하나 추가된다.
Adaptive learning rate
Learning rate는 딥 러닝 모델 성능에 지대한 영향을 미친다. 그래서, 이 값을 적절한 값으로 정하는 것은 상당히 중요하지만, 동시에 상당히 어렵다. 목적 함수가 parameter에 따라 매우 다르게 반응하는 경우가 있다. 앞서 설명한 momentum이 이 현상을 어느 정도 완화할 수 있으나, momentum parameter라는 새로운 hyperparameter가 추가되어, 오히려, 적절한 hyperparameter 쌍을 찾기 더 힘들어질 수 있다.
각 parameter별 최적의 learning rate가 현재 point의 gradient에 따라 다르다면, adaptive하게 learning rate를 정하는 알고리즘이 이를 완화할 것이다. 첫 번째로 소개될 AdaGrad algorithm은 각 parameter의 gradient 크기를 저장하여 업데이트할 때 그 크기로 나눠준다. 즉, 너무 큰 gradient가 나왔을 때는 속도를 줄여주고, 너무 작은 gradient는 어느 정도 큰 step으로 이동하게 보정해 주는 효과가 있다.
AdaGrad
Initialize $\mathbf{r}=0$ (squared gradient값을 모을 변수 설정)
While tolerance 만족이 안 되면
- Gradient를 계산한다. $\mathbf{g}=\frac{1}{m}\nabla_\theta\sum^m_{i=1}L\left(f\left(\mathbf{x}^{(i)};\theta\right),\mathbf{y}^{(i)}\right)$
- Squared gradient를 모은다. $\mathbf{r}\leftarrow\mathbf{r}+\mathbf{g}\odot\mathbf{g}$
- Learning rate를 보정하여 update를 계산한다. $\Delta\theta\leftarrow-\frac{\epsilon}{\delta+\sqrt{\mathbf{r}}}\odot\mathbf{g}$
- Update. $\theta\leftarrow\theta+\Delta\theta$
End While
위 과정에서 알 수 있지만, 변수 $\mathbf{r}$에 계속해서 각 parameter로 인한 gradient의 크기가 누적된다. 이는, 학습이 진행될수록 learning rate를 계속해서 줄이게 된다. 즉, 학습이 길게 진행된다면, 성능이 크게 저하하게 된다. 이를 해결하기 위해, 지수 이동 평균(exponential moving average)을 이용하여 축적하는 방식으로 바꾸게 된다. 지수 이동 평균은 최근에 높은 가중치를 주고 오래된 과거의 가중치를 낮게 주는 일종의 가중 이동 평균이다. 이를 활용한 알고리즘이 RMSProp algorithm이다. 이동 평균을 조절하는 hyperparmeter인 $\rho$를 새로이 도입해야 하지만, AdaGrad보다 더 좋은 성능을 보여준다. 상세한 알고리즘은 아래와 같다.
RMSProp
Initialize $\mathbf{r}=0$
While tolerance 만족이 안 되면
- Gradient를 계산한다. $\mathbf{g}=\frac{1}{m}\nabla_\theta\sum^m_{i=1}L\left(f\left(\mathbf{x}^{(i)};\theta\right),\mathbf{y}^{(i)}\right)$
- Squared gradient를 모은다. $\mathbf{r}\leftarrow\rho\mathbf{r}+(1-\rho)\mathbf{g}\odot\mathbf{g}$
- Learning rate를 보정하여 update를 계산한다. $\Delta\theta\leftarrow-\frac{\epsilon}{\sqrt{\delta+\mathbf{r}}}\odot\mathbf{g}$
- Update. $\theta\leftarrow\theta+\Delta\theta$
End While
여기에, 아래와 같이 momentum을 추가하는 알고리즘도 가능하다.
RMSProp with Nesterov’s momentum
Initialize $\mathbf{r}=0$
While tolerance 만족이 안 되면
- Gradient를 계산한다. $\mathbf{g}=\frac{1}{m}\nabla_\theta\sum^m_{i=1}L\left(f\left(\mathbf{x}^{(i)};\theta+\alpha\mathbf{v}\right),\mathbf{y}^{(i)}\right)$
- Squared gradient를 모은다. $\mathbf{r}\leftarrow\rho\mathbf{r}+(1-\rho)\mathbf{g}\odot\mathbf{g}$
- 속도 벡터를 update. $\mathbf{v}\leftarrow\alpha\mathbf{v}-\frac{\epsilon}{\sqrt{\mathbf{r}}}\odot\mathbf{g}$
- Update. $\theta\leftarrow\theta+\mathbf{v}$
End While
Adam
지수 이동 평균을 이용하여 성분별 gradient의 크기를 누적하기 때문에, 이는 최근 값에 bias될 것이다. 즉, 초깃값은 데이터에 비해 너무 작은 값이 나올 수 있다. 아래 그림을 참고하면, 시각적으로 알 수 있다.
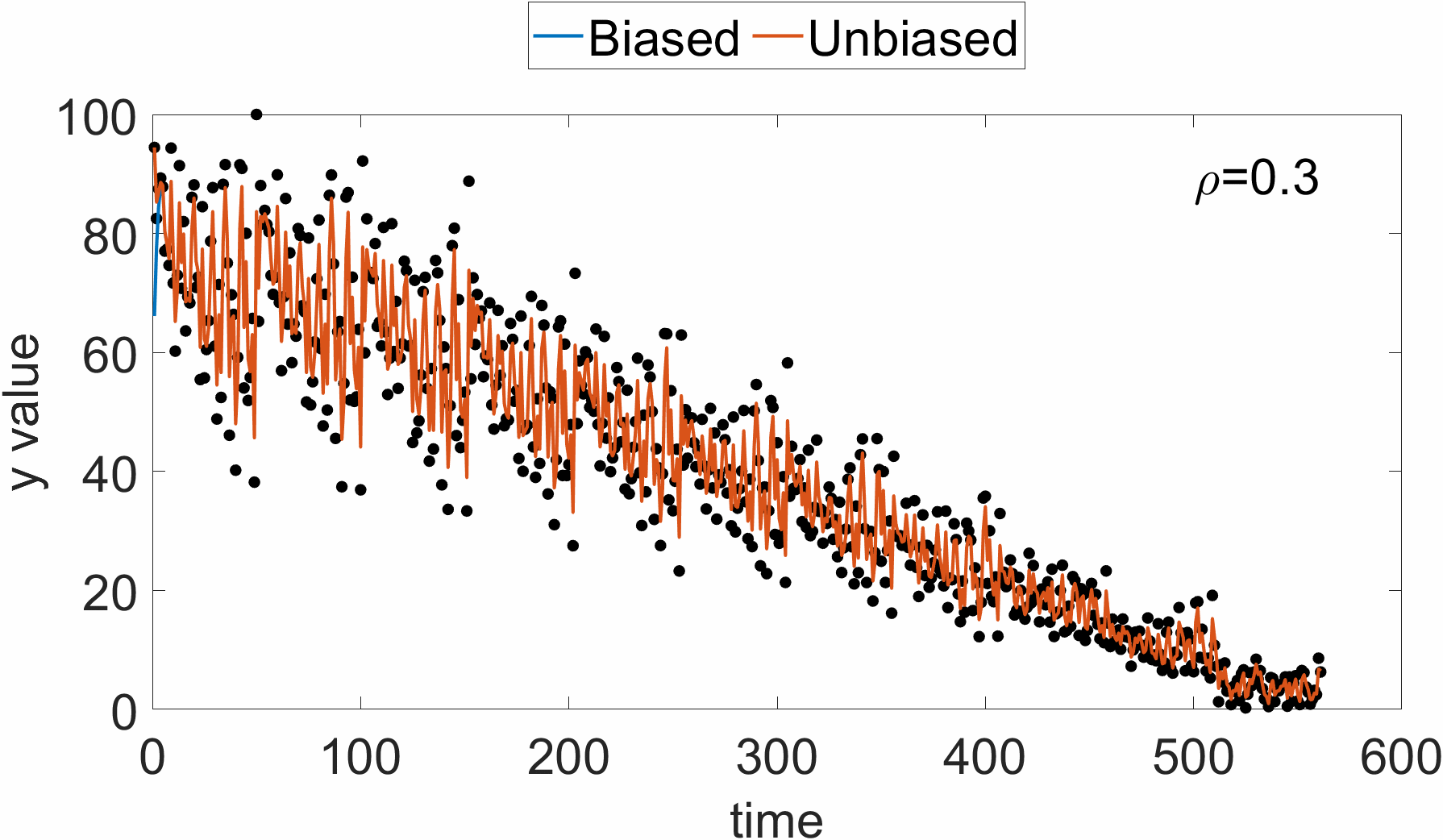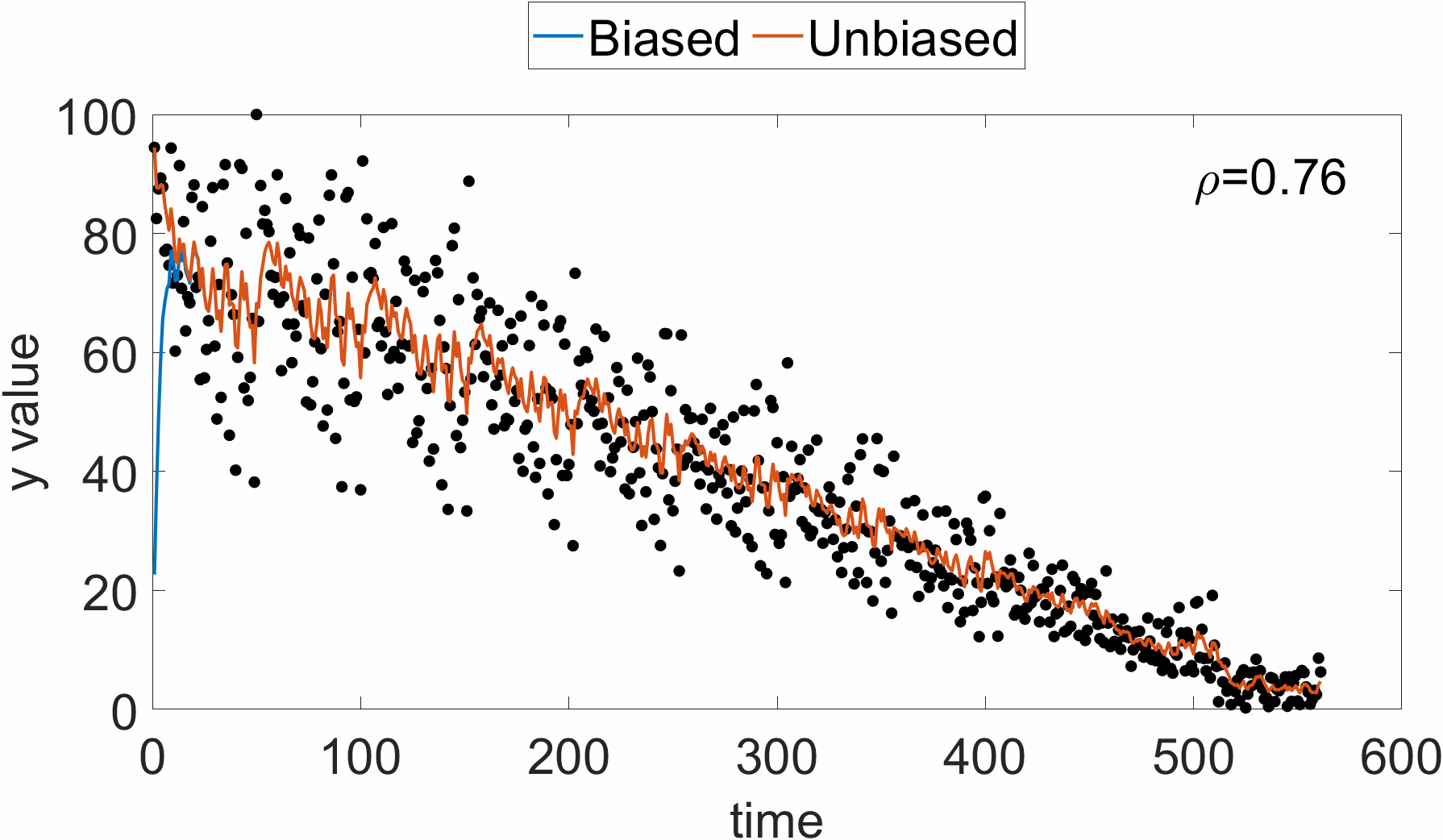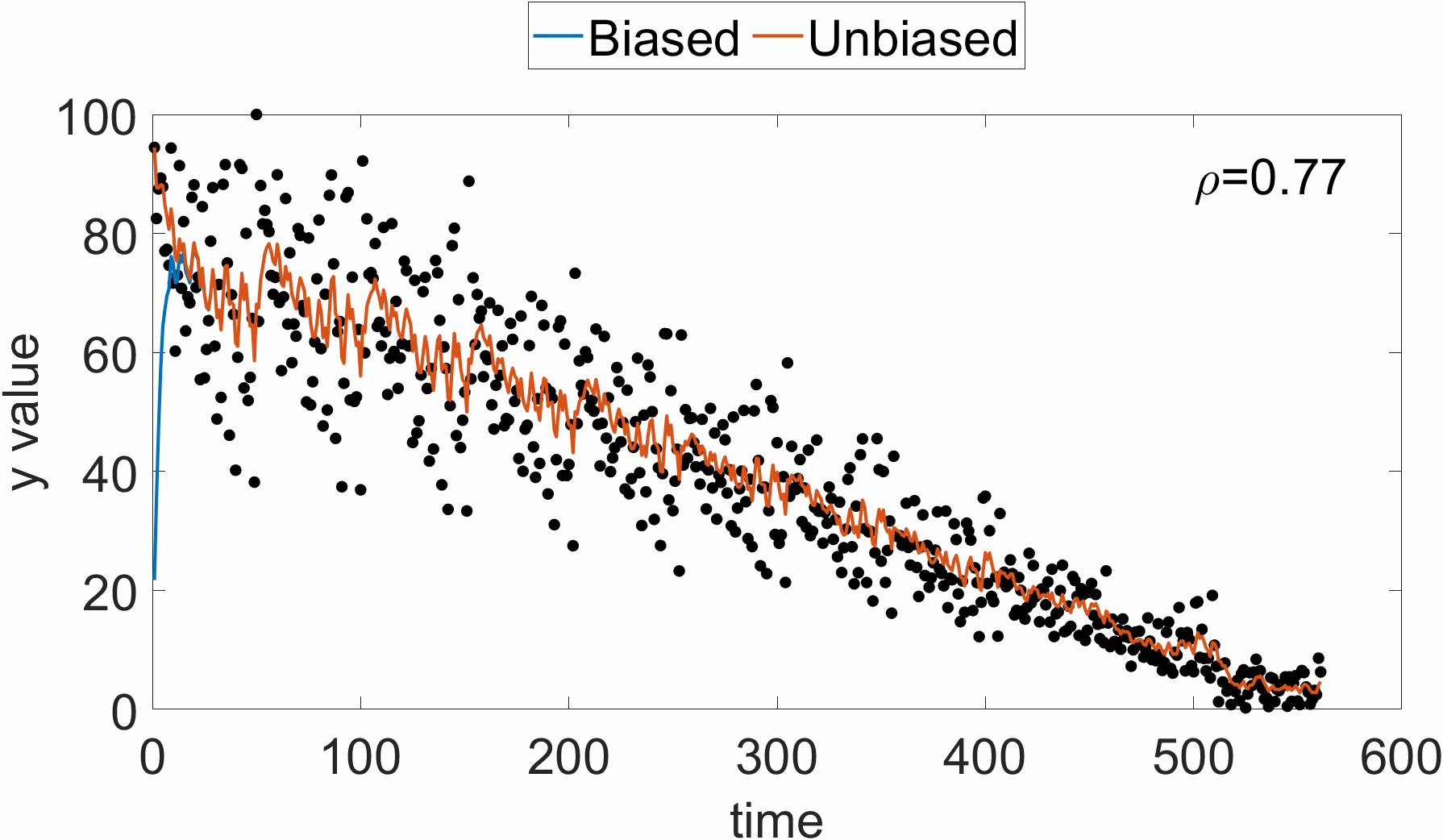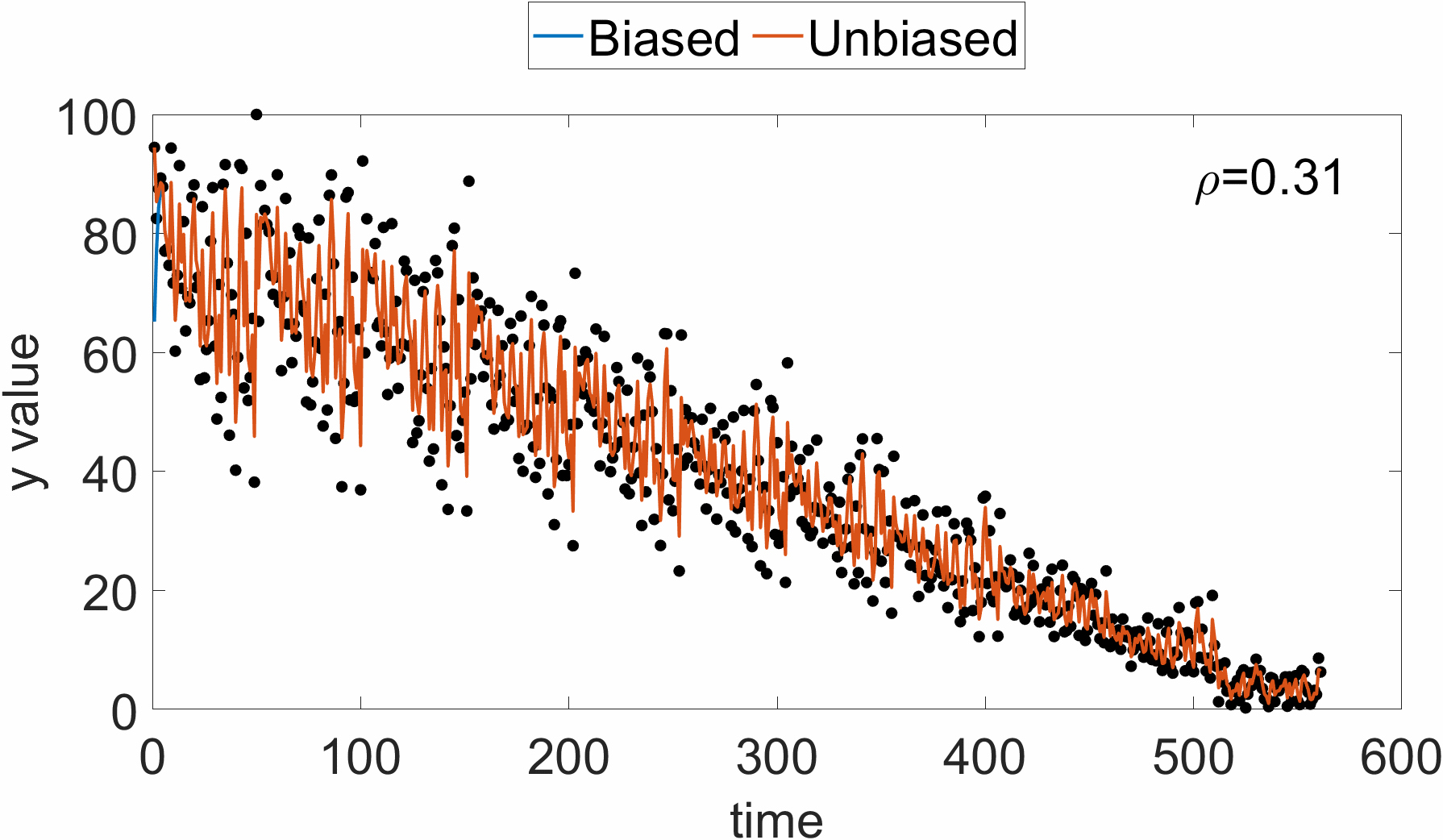
$t$-step에서의 $\mathbf{r}_t$값을 살펴보면 아래와 같다.
\[\begin{equation} \mathbf{r}_t=(1-\rho)\sum^t_{i=1}\rho^{t-i}\mathbf{g}_i\odot \mathbf{g}_i \end{equation}\]$t$-step 지수 이동 평균 $\mathbf{r}_t$의 기댓값은, 각 포인트에서의 gradient 기댓값이 유사하다고 가정하면, 아래와 같이 전개할 수 있다.
\[\begin{equation} \mathbb{E}(\mathbf{r}_t)=\mathbb{E}(\mathbf{g}_t\odot\mathbf{g}_t)(1-\rho)\sum^t_{i=1}\rho^{t-i}+C=(1-\rho^t)\mathbb{E}(\mathbf{g}_t\odot\mathbf{g}_t) + C \end{equation}\]즉, $t$-step 지수 이동 평균값에 $1/(1-\rho^t)$ 만큼 무게를 준다면, unbiased 된 값을 이용할 수 있다. RMSProp은 이런 biased된 값을 그대로 사용하는 한계점이 있다. 이 점을 보완한 지수 이동 평균을 이용한 알고리즘이 Adam algorithm이다. Learning rate에 대한 적응성뿐만 아니라, momentum을 반영할 때도 지수 이동 평균을 이용한다. 상세한 알고리즘은 아래와 같다.
Adam
Initialize $\mathbf{s}=0$ (momentum gradient값을 모을 변수 설정)
Initialize $\mathbf{r}=0$ (squared gradient값을 모을 변수 설정)
Initialize $t=0$ (time-step)
While tolerance 만족이 안 되면
- Gradient를 계산한다. $\mathbf{g}=\frac{1}{m}\nabla_\theta\sum^m_{i=1}L\left(f\left(\mathbf{x}^{(i)};\theta\right),\mathbf{y}^{(i)}\right)$
- $t\leftarrow t+1$
- Gradient를 모은다 (momentum or 1st moment). $\mathbf{s}\leftarrow\rho_1\mathbf{s}+(1-\rho_1)\mathbf{g}$
- Squared gradient를 모은다 (2nd moment). $\mathbf{r}\leftarrow\rho_2\mathbf{r}+(1-\rho_2)\mathbf{g}\odot\mathbf{g}$
- Momentum(1st moment)의 bias 수정. $\hat{\mathbf{s}}\leftarrow\frac{\mathbf{s}}{1-\rho_1^t}$
- Squared gradient(2nd moment)의 bias 수정. $\hat{\mathbf{r}}\leftarrow\frac{\mathbf{r}}{1-\rho_2^t}$
- 속도 벡터를 update. $\Delta\theta\leftarrow-\epsilon\frac{\hat{\mathbf{s}}}{\delta+\sqrt{\hat{\mathbf{r}}}}$
- Update. $\theta\leftarrow\theta+\Delta\theta$
End While
마치며
적절한 learning rate를 찾는 것은 수치 최적화를 이용하여 연구하는 사람들의 평생 숙제이다. 실제로 모델을 이용하여 모수 추정, 최적 전략 수립 등을 연구해 본 사람은 체감할 수 있을 텐데, 여기에 지나치게 많은 시간을 쏟기가 아무래도 쉽지 않다. 데이터에 맞는 모델을 찾고, 적절한 hyperparameter를 찾아 데이터 분석하는 데에도 큰 시간이 든다. Adam은 여러 문제를 해결한 알고리즘으로, 여러 경우에서 사용하기 좋다. RMSProp도 많이 쓰이는 알고리즘이다. 이 두 알고리즘의 원리를 이해하고, 더하여, (Nesterov) momentum에 대한 이해가 있다면, 작은 범위의 hyperparameter 조절로 지나치게 큰 범위에 있는 learning rate를 adaptive하게 정할 수 있다. 그러면, 최근까지 많이 쓰이는 learning rate 알고리즘들은 이해하게 될 것이다.
수정사항
[2023.11.25] 문맥 정리 및 맞춤법 검사